Re: CHAT GPT3 - a revolução da Inteligencia Artificial
Neste repositório github tem alguma informação interessante, nomeadamente sobre o que é que foi utilizado para treinar o ChatGPT e não só:
https://gist.github.com/veekaybee/6f888 ... 5c7e870698
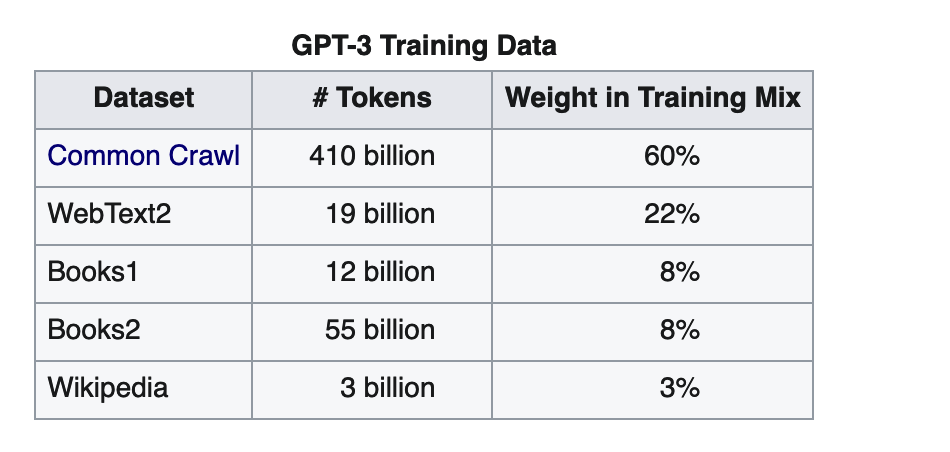
No que diz respeito ao dataset, o grosso terá sido uma pesquisa pela internet com 410 mil milhões de tokens (tokens são um encapsulamento/codificação de palavras e representa essencialmente elementos semânticos). Isto terá sido o grosso dos dados. Além disso utilizou um dataset extraído/filtrado do reddit, dois de datasets de papers e livros (um suspeita-se aparentemente que se tratou do libgen, que é uma ferramenta pirata que disponibiliza papers e livros tecnicos/cientificos) e finalmente o wikipedia também terá feito parte. Estão indicados os supostos pesos durante o treino (cada dataset ou token não tem que pesar o mesmo). Esta informação também está no wikipedia por sinal, na página do GPT-3 que é o modelo base sobre o qual o ChatGPT é construído (link).
https://gist.github.com/veekaybee/6f888 ... 5c7e870698
No que diz respeito ao dataset, o grosso terá sido uma pesquisa pela internet com 410 mil milhões de tokens (tokens são um encapsulamento/codificação de palavras e representa essencialmente elementos semânticos). Isto terá sido o grosso dos dados. Além disso utilizou um dataset extraído/filtrado do reddit, dois de datasets de papers e livros (um suspeita-se aparentemente que se tratou do libgen, que é uma ferramenta pirata que disponibiliza papers e livros tecnicos/cientificos) e finalmente o wikipedia também terá feito parte. Estão indicados os supostos pesos durante o treino (cada dataset ou token não tem que pesar o mesmo). Esta informação também está no wikipedia por sinal, na página do GPT-3 que é o modelo base sobre o qual o ChatGPT é construído (link).
Originally I asked about this on Twitter and didn't come up with much. My Twitter Thread Question on Training Data. But since then, independent researchers have been discussing and verifying the very opaque training data behind the OpenAI models.
A key component of GPT-3x models are Books1 and Books2, both of which are shrouded in mystery. Researchers have attempted to recrate the data using OpenBooks1 and 2.